
When cooking different recipes, adding spices can change the flavor of a dish entirely. Many individuals love adding heat and spice to recipes to give off taste and accentuate a dish. There are several different ingredients that home cooks and chefs can use to spice up and flavor their dishes. On the spice rack, two of the main ingredients that people use are chili powder and chili flakes. While the two may derive from the same pepper, they both bring forth different things to a dish in terms of intensity.

©xpixel/Shutterstock.com
What is Chili Powder
Chili powder is made from chili peppers that are dried out and then ground up. The powder itself is mixed with not only the chili pepper itself but also several other spices. Many companies make chili powder with cumin, garlic powder, and salt. These other spices add texture to the powder and can also elevate the intensity of the chili powder itself. Chili powder is used specifically in recipes that are from Southern regions and Central America, such as Tex-Mex recipes.
How Long Has Chili Powder Been Around
Chili powder has been around for decades and stems back to the times when people began to use chili peppers. Central American countries were the first to use chili peppers in cooking and recipes. Christopher Columbus was the first one who brought chili peppers back to European nations when he discovered several countries in Central America. Both Columbus and various people in Central America began to use chili peppers in various ways, including grounding them into powders for recipes.
- The must-have convenient reference guide for every home cook!
- Includes more than 8,000 substitutions for ingredients, cookware, and techniques.
- Save time and money on by avoiding trips to grab that "missing" ingredient you don't really need.

Centuries later, companies began to create and package chili powder in mass production for individuals to purchase them at the store and have them in their own homes. Today, chili powder is sold in various forms, by various companies, and ranges in heat scales.

©Harshada Raju/Shutterstock.com
What Are Chili Flakes
Chili flakes are a spice that is mainly seen and found in Italian restaurants and pizzerias. The spice is made from chili peppers, like chili powder, but prepared differently. They are also ground, but they are then tried into flakes, rather than drying and grounding them. Chili flakes are made from various types of chili peppers, however, are made with just peppers alone.
The History Behind Chili Flakes
Similarly to chili powder, chili flakes have been around since chili peppers were harvested and used for cooking and recipes. Stemming back to Central American empires, such as the Mayans and Aztecs, chili flakes were created using chili peppers once discovered. In addition to being used for cooking, many cultures also used chili peppers for medicine.
When chili peppers spread throughout Europe and the Americas, many people began to use chili flakes and chili peppers commercially. Today, chili flakes are used in Mexican, Italian, and Asian recipes, as well. They are used in each culture to heat and spice up food during cooking and afterward as an additive spice.

©Amarita/Shutterstock.com
How The Two Chili Products Differ
Ingredients
Chili flakes are made simply from chili peppers dried up and broken down into flakes. However, chili powder is made with far more than chili peppers. Other spices are added, such as garlic powder, oregano, and even salt.
Heat
Chili powder happens to be less spicy than chili flakes. The reason behind this is due to the ingredients that are used to make chili powder. Chili flakes are made with chili peppers of varying kinds, while chili powder is made with other spices like garlic powder, which dulls the heat.
Flavors and Texture
Chili powder has a more complex taste due to the combination of several spices. Different spices can create a different flavor palette for a dish. Chili powder is also smooth, as it's ground up into powder form. On the other hand, chili flakes have an extremely intense chili flavor as they are made from only chili flakes. The texture is much more rough, as the flakes are not as smooth and refined as powder.
Uses In The Kitchen
Chili powder is usually used in a recipe while cooking. Many times, it is added to sauces and soups, even stews, while it's still cooking. Chili flakes are used, instead, to spice food and items afterward to add extra heat and flavor.

©Endorphin_SK/Shutterstock.com
The Bottom Line
Chili powder and chili flakes are similar in that they both come from dried chili peppers. They share a rich history from Central American cultures and nations that first harvested chili peppers for culinary and medicinal uses. However, over the years, the two spices and heat additives in the kitchen have vastly different tastes, textures, and uses.
Chili flakes are an after-addition, usually to add more heat and flavor to food once it's already cooked. It's created with just chili peppers and chili peppers only. On the other hand, chili powder is used while cooking as a recipe ingredient. It's made from not just chili peppers but also other spices like salt, pepper, oregano, and garlic powder. It's also less spicy and hot than chili flakes overall.
- The must-have convenient reference guide for every home cook!
- Includes more than 8,000 substitutions for ingredients, cookware, and techniques.
- Save time and money on by avoiding trips to grab that "missing" ingredient you don't really need.
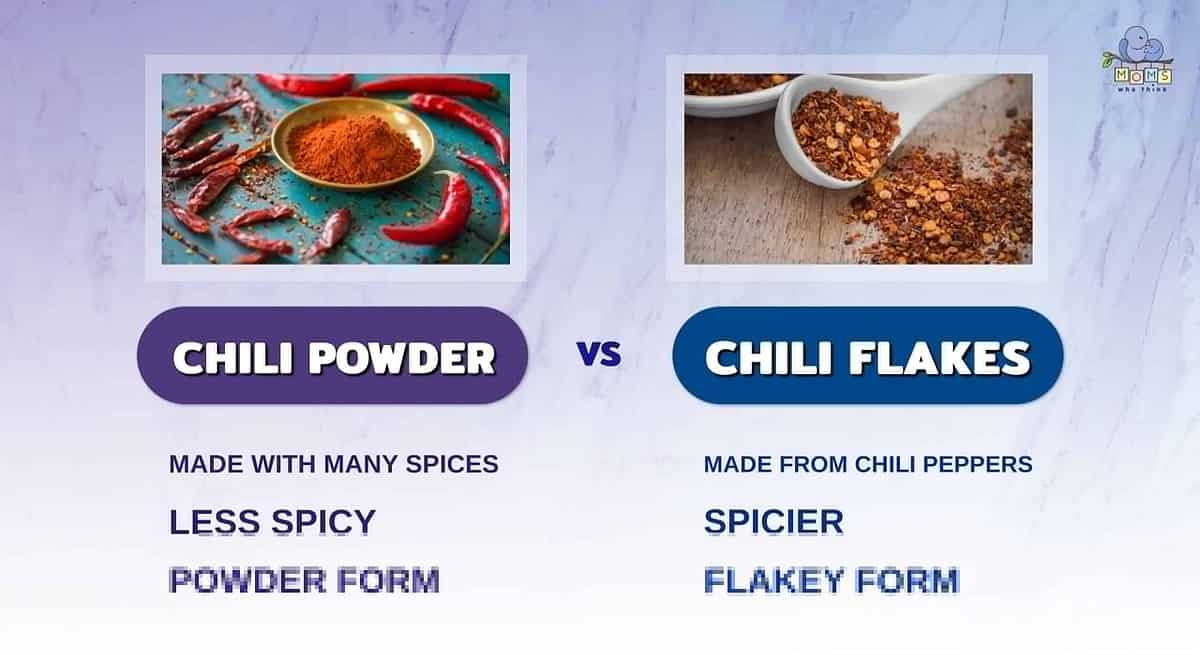
Chili powder and chili flakes may seem as if they are the same, but they actually have a few differences that you may not realize. Let's recap this article and find out what some of the differences between chili powder and chili flakes are:
- Surprisingly, chili powder is less spicy than chili flakes, which tend to have intense heat.
- The most obvious difference is chili powder comes in ground form, while chili flakes have a flaky texture.
- One that might not be so obvious is chili flakes are simply made with varying chili peppers. On the other hand, chili powder can be made with different spices, such as garlic powder and oregano.
Try This Meatless Monday Chili Mac
Print
Meatless Monday Chili Mac
 (No Ratings Yet)
(No Ratings Yet)![]() Loading…
Loading…
- Yield: 8 servings 1x
Ingredients
1 large onion, chopped
1 large green pepper, chopped
1 Tablespoon olive oil
2 garlic cloves, minced
2 cups water
1 1/2 cups uncooked elbow macaroni
1 can (16 ounces) mild chili beans, undrained
1 can (15 1/2 ounces) great northern beans, rinsed and drained
1 can (14 1/2 ounces) diced tomatoes, undrained
1 can (8 ounces) tomato sauce
4 teaspoons chili powder
1 teaspoon salt
1 teaspoon ground cumin
1/2 cup fat free sour cream
Instructions
1. In a large saucepan, sauté onion and green pepper in oil until tender.
2. Add garlic; cook 1 minute longer.
3. Stir in the water, macaroni, beans, tomatoes, tomato sauce, chili powder, salt and cumin.
4. Bring to a boil. Reduce heat; cover and simmer for 15 to 20 minutes or until macaroni is tender.
5. Top each serving with 1 Tablespoon sour cream.
Nutrition
- Serving Size: 1¼ cups
- Calories: 214
- Sodium: 857mg
- Fat: 3g
- Saturated Fat: 1g
- Carbohydrates: 37g
- Fiber: 8g
- Protein: 10g
- Cholesterol: 3mg
The image featured at the top of this post is ©Ground Picture/Shutterstock.com.
- The must-have convenient reference guide for every home cook!
- Includes more than 8,000 substitutions for ingredients, cookware, and techniques.
- Save time and money on by avoiding trips to grab that "missing" ingredient you don't really need.